Two-Step Formalization
- Converting data source to formal domain knowledge semantics
- Formal domain consensus modeling and re-using domain ontologies
- Decoupling data source from formal domain consensus modeling
Converting data source to formal domain knowledge semantics
There are the W3C formal standard languages RDF, RDFS and OWL with built-in logic, and their respective foundational ontologies.
Formal here means adhering to the model theory of the languages. This model theory is based on set theory and first-order logic, and enables machine interpretability of their semantics.
There are domain ontologies, own and external ones, based on those standards.
Formal RDF-data can then be expressed using these ontologies, making the data machine interpretable.
But how do we ‘RDF-ize’ or convert source data, e.g. in an XML or SQL database, to RDF?
The source data models, though capturing consented domain knowledge, are often localized through natural language and personal representations such as abbreviations and cryptic naming, not fully described. In other words they are not always stating meaning explicitly, and most importantly they are not expressed in a machine-interpretable language of logic.
This can be done in 1 step only using source specific semantics, without re-using existing domain ontologies and/or without modeling in broader domain consensus.
But this method does not bring semantic interoperability, it creates semantic silos.
A second way is to do it in 1 step, but enabling semantic interoperability, re-using consented models. Here the problem is the direct or ‘hard’ coupling of the data source semantics with the formal domain semantics.
We will discuss how to overcome the semantic silo and the hard coupling respectively.
Formal domain consensus modeling and re-using domain ontologies
Formalizing semantics means in the first place using the foundational ontological elements of RDF/S and OWL.
This brings the advantages of making the assumptions explicit, and the semantics natural language-independent.
But semantic interoperability only comes about if a large enough community uses the same basic modeling patterns and/or the same domain ontologies, i.e. creating formal data bearing semantics beyond that of the source data model.
At the end we want to query and machine reason with large, often merged, formal data sets, requring broad domain semantic consensus.
Consider for example a group of scholarly projects about correspondence between a group of scientists and artists of a certain period. The content of 1 project can overlap with that of another project, but is mostly different. The data sets are actually complementary. From a research point of view it would be very interesting to be able to connect the different data sets to benefit from the complementarity and discover new facts, e.g. how people have influenced each other’s thoughts and intellectual products. The linking is only possible with a minimal effort of domain consensus modeling. It is a waist of effort to have for each data set another class modeled for ‘Person’, or ‘Text’, or ‘Letter’.
That cross data source modeling is not obvious, rather painstaking at times, but it pays off into the near future, not only preventing modeling repetition, but enabling semantic interoperability.
Decoupling data source from formal domain consensus modeling
Very generally speaking, entities that are directly or ‘harldy’ coupled are likely more strongly influenced by the other’s change, in 1 or both directions, compaired to entities that are indirectly coupled.
We discuss now in detail the two-step formalization (Figure 1).
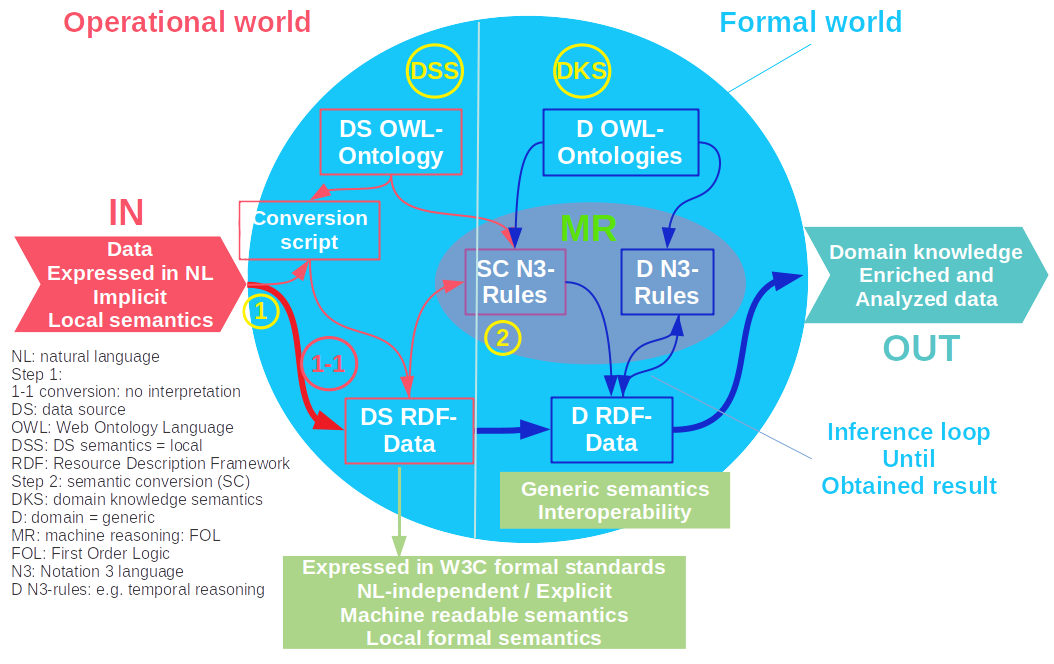
Source data can be directly converted in 1 step to the domain knowledge expressed with more generic formal ontological classes and properties, bearing a broader consensus than source-specific models. There is also the many-to-many model issue. The first ‘many’ applies to all the database models being independent from each other, i.e. semantically not linkable. The second ‘many’ refers to the semantic space based on the W3C standard languages, and domain ‘upper’ ontologies, providing highly reusable, hence unifying semantics.
To make both worlds and their semantics less hardly depending on each other, but still complementary, they are decoupled in a sound and convenient way using the 2-step formalization (2SF), permitting them their own developmental iterations.
The source data can be in XML or in an SQL database, using natural language descriptors. The data model is mostly not shared with other projects or databases, and meaning is often not explicitly stated. The data cannot be reasoned upon by a machine because of the lack of built-in logic in the language expressing them. In the first step of the formalization process there is a 1-1 conversion of the source data to RDF. 1-1 here means that the semantics are not interpreted and not expressed in formal domain knowledge. The syntax of the original model is converted to the RDF data model, and making all of the existing semantics explicit and machine interpretable. The RDF-data also become largely natural language independent. The data can then be stored in this format in an application RDF database (or triple store), or stored as Turtle file. The data can then be directly consumed as Turtle file or queried with SPARQL from the triple store. In a second step the source-specific RDF-data are converted to explicit, semantically enriched RDF-data using domain ontologies, enabling semantic interoperability, independent from the data source and application semantics. Note: the ultimate goal is to directly produce data in RDF, without XML or SQL, but still in 2 steps, permitting the semantic connection of disparate RDF-graphs.